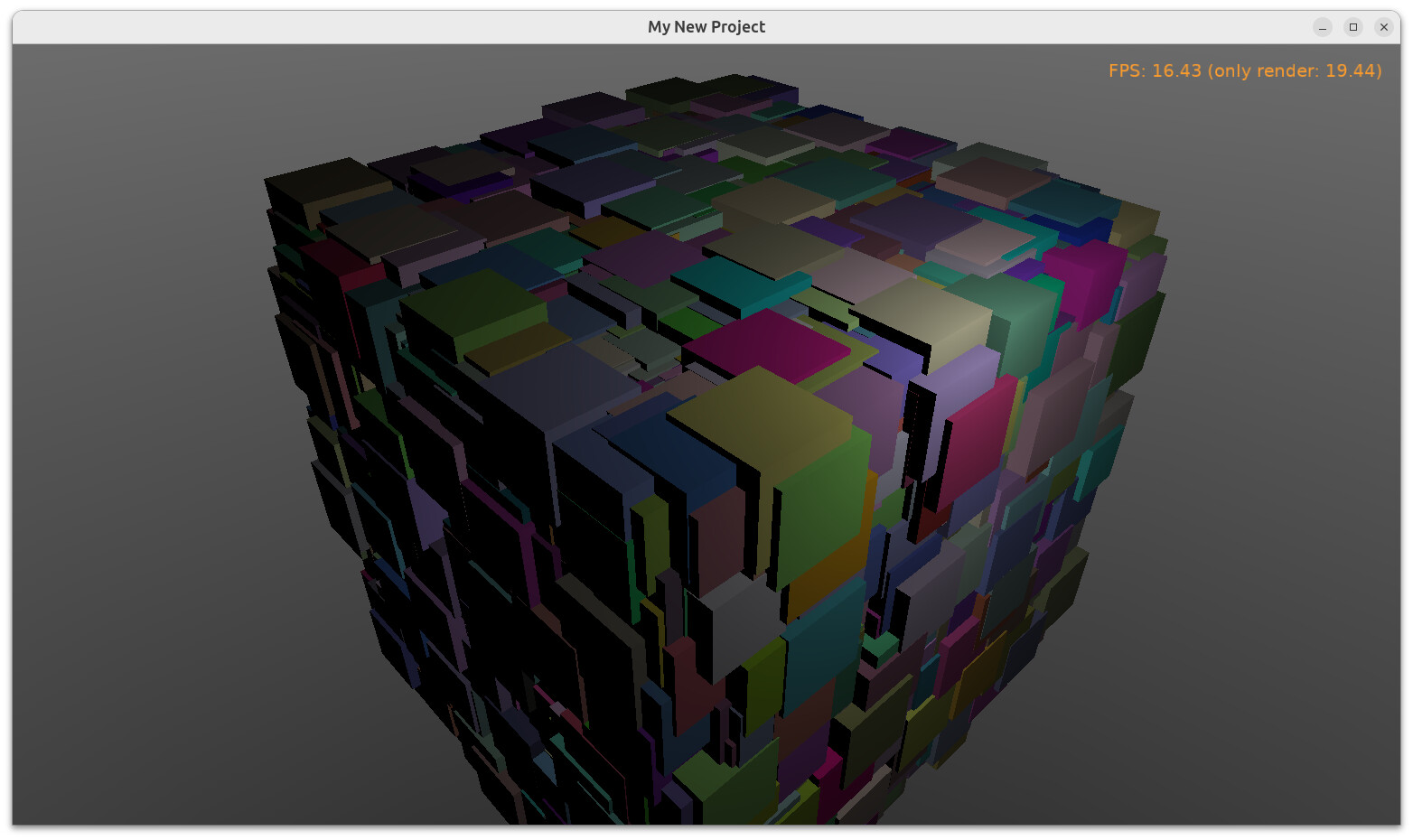
I played a bit with small engine optimizations today.
The GitHub - michaliskambi/many-cubes with 10 thousand cubes now works at 16.4 FPS (was at 9-10 FPS this morning). This is still a TODO naturally, 16 FPS is not satisfactory, but it’s a significant increase that may positively affect more use-cases. It means that new code executes in 0.579 fraction of the old one ((60 / 16.4) / (60 / 9.5)), so that’s not bad progress
Or, to measure in the other way (“how much you can now increase NumCubes while keeping reasonable FPS”):
1k, 2k, 3k cubes now run at 60 FPS
4k cubes now run at 38 FPS
with 5k cubes you now have 30 FPS, so on the fence of “playable”.
These measurements of course are specific to my system,
~5 years old mid-range laptop with Nvidia ( NVIDIA GeForce RTX 3050 Ti Laptop GPU/PCIe/SSE2 )
Linux x86_64
Tested with FPC 3.2.2 and recent FPC 3.3.1 (out of curiosity, I tested whether FPC version affects performance in a noticeable way; it doesn’t, at least not in this testcase).
More optimizations in the engine I planned of course, so I will keep returning to this testcase and see how far can we push it without introducing game-specific optimizations mentioned in this thread and in README (so the demo deliberately uses TCastleBox is most simple way, doesn’t try to use TCastleTransformReference, LODs, everything is in frustum etc.)
When I render 10000 of them, nvidia rtx 5090 and radeon embedded do at 24-23 fps when compiled with FPC. Delphi compilation performed worse giving me 16 fps.
However, when I spread them a bit, instead of position = random (+/- 10) I went to +/- 20 the fps dropped to 20.
When I spread them more, +/- 100, then fps drops to about 12-13. See attached picture. Delphi-compiled ran at 7-8 fps.
I have changed one light into directional, and reduced the second one to 10 intensity & 10 radius. No noticeable change in fps here, however in other tests larger radius for Spot/PointLight (with walk navigation) has understandably bigger impact on fps.
[Edit: For full info I should add I run it on win11, amd ryzen 9 9950x4d with radeon GPU embedded, 128GB ram ]
For a comparison, 10,000 textured scene clones rendered at 28 fps.
The src code is here. Not very clean but I have been changing it too many times my-new-project-0.1-src.zip (54.7 MB)
– change the cube’s url (Scene1) to ‘castle-data:/wooden_wall.gltf’ (my mistake packaging)
– press F1 as many time you wish to add 1,000 cubes
This observation makes sense. Because in that case, the occlusion culling doesn’t help, and likely actually wastes time (you can try disabling it, with O key), because small cubes are unlikely to be occluded.
These are the “details in which devil hides” that I mentioned in one of above posts :), and why reasoning from some tests → only transfers some conclusions into other projects.
What the cubes actually represent, what is the typical camera matters. E.g. if cubes are buildings and camera is on the ground, then occlusion culling will help greatly.
Thanks for testing – this also makes sense.
( Note that TCastleBox is internally also making a TCastleScene, so 10k TCastleBox is also 10k scenes. )
Putting texture on a box doesn’t hurt – it’s practically free on modern GPUs.
And the fact that now you have 10k same objects, helps greatly.
So in total, this is actually easier to render than 10k untextured cubes with random colors. Makes sense you get more FPS.
You can possibly now activate Viewport.DynamicBatching and enjoy even more FPS (Again, the “devil in details” here may determine whether these cubes will batch or not.)
I completely forgot about DynamicBatching existence.
I keep in mind the original quest of having thousand of cube-like houses with ability to see them from above, so by default I turn the occlusion culling off. However in this scenario it changed the performance just by single frames. Most of my tests here were done with cubes placed on a flat ground (Y = 0) to be true to the original question.
I initially thought about switching the occlusion “on” while on the ground, and “off” when seen from above. But with so many objects seen all at once, the amount of calculation on CPU, I guess, simply nullify the benefit of using occlusion here at all. I believe the proposed cube-houses needs to be grouped somehow and excluded from display by the group not individually, otherwise it’ll always be one of the big bottlenecks. Nevertheless, original post was about 1,000 cubes, and we see that even 10,000 are still do-able.
Competition between separate objects vs clones is getting tight If you continue I’ll stop advocating clone But seriously, I’m glad you found a way to optimise this stuff. It will be, for sure, of much help in my own project too!
Indeed, that is one idea. A few years ago we had alternative occlusion method, hierarchical occlusion query based on this insight. However, in practice the “hierarchical occlusion query” was always outperformed by the simple approach (used for current occlusion culling), and it was quite complicated to maintain, so we removed it.
( I’m not saying the technique in itself was definitely inefficient. It was implemented by much younger version of Michalis in a much younger version of the engine :). Maybe it just didn’t get enough polish / attention as it should, to be really beneficial. )
The future occlusion methods I’m looking forward revolve around using GPU more. Using Z-buffer, with possible “pre-pass” (additional rendering pass that only sets Z-buffer), and generating mipmaps from it, to use to detect occlusions. With compute shaders, one can offload even more work to GPU, like testing against these mipmaps of Z-buffer. Some of the links I have around the subject:
Oh indeed we get better All this stress-testing is beneficial.
Oh, I’m sure the TCastleTransformReference approach (which I understand you mean by “clone” – not to be confused with TCastleScene.Clone method) will remain a good advise, when only possible. It conserves resources in a “definite” way, there’s just really only 1 target in memory to which we can have a zillion of pointers.
In fact, using GPU instancing we could possibly improve both the TCastleTransformReference and also allow more things to use similar approach (e.g. 10000 cubes that only differ in color could use this too).
We have lots of ideas how things could be optimized